Redis 授权有 2 中方式:
- 只使用密码。
- 用户名 + 密码。
只使用密码
在配置文件 redis.conf 中搜索 requirepass 或 # requirepass,将该行的注释符号 # 去掉,并在等号后面输入你想要设置的密码。例如:
1 | requirepass Passw0rd |
客户端访问:
1 | 命令中使用密码 |

大圣,此去欲何?踏南天,碎凌霄。若一去不回…… 便一去不回!
VxeTable 主要是支持虚拟滚动。
表格的数据为对象的数组,手动固定列 (也可以使用循环)。
1 | <template> |
使用任务队列、异步、并发且限制并发数量的主要控制流程,这个模型在大文件分片上传时能够用到。
1 | // 异步、并发、最大并发数执行任务。 |
Hexo 主题中使用 Mermaid 按照官方的介绍文档会报错:
Hexo 主题中使用 Mermaid 的步骤可以写死为:
在 head.ejs 中引入 Mermaid:
1 | <!-- mermaid.js 需要在 require.js 前面加载 --> |
在 after-footer.ejs 中初始化 Mermaid:
1 | <script> |
示例:
1 | flowchart TB |
效果:
flowchart TB
A[Client 分片上传文件] -- 发送 --> S1[分片 1] & S2[分片 2] & S3[分片 3]
S1 & S2 & S3 --> Gateway
Gateway --> DSC1
Gateway -- 保证所有分片都发送到 --> DSC2
日志系统输出的是 JSON 格式的日志,每行一个 JSON 对象,例如:
1 | {"func":"newdtagent/service.(*WatchdogService).UpdateAgent():63","level":"info","msg":"升级 Agent","time":"2023-02-17 14:03:42","version":"v1.0"} |
Go 通常可以使用以下 3 种方式实现超时:
推荐使用 Cancel Context 的方式实现超时功能,因为区分是正常结束还是超时结束比较容易。
TimeoutContext 的特点:
案例代码:
1 | package main |
正常输出:
1 | Query Start... |
超时输出:
1 | Query Start... |
可以使用 watchdog 控制某些耗时操作的超时时间,当超时的时候执行指定的操作,例如中断线程、重置 Redis key 的超时时间等。Apache 的 commons-exec 包中提供了 watchdog 的实现供我们使用 (源码为文章后面的 Watchdog.java)。
According to wikipedia - watchdog is an electronic timer that is used to detect and recover from computer malfunctions.
下面的例子执行拼接字符串的耗时操作,定义了一个 watchdog,超时时间为 1S,超时后 watchdog 中断线程结束字符串拼接操作。
1 | import org.apache.commons.exec.Watchdog; |
输出:
1 | 开始时间: 01:51:40 |
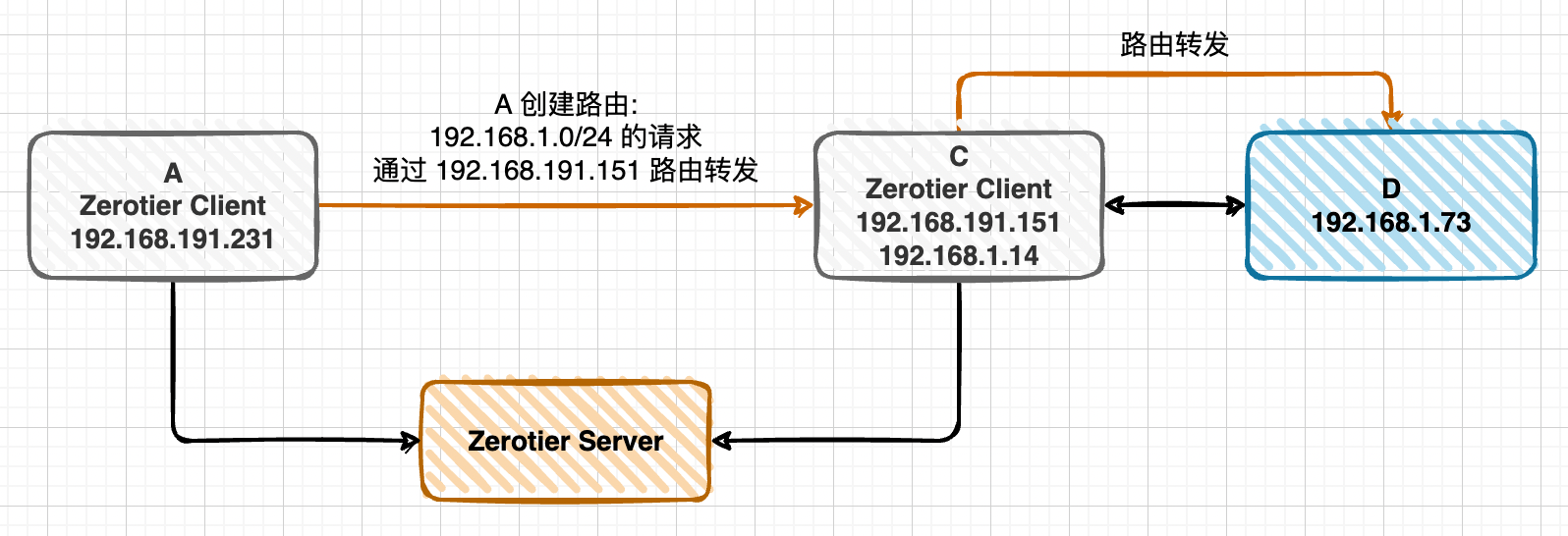
在 OSX Monterey 使用 VPN 中介绍了 Monterey 使用 L2TP-IpSpec VPN 的问题,并且使用 Windows Server 2016 进行中转处理的方案,虽然勉强能用,但是不够方便,本文中介绍了几种其他方案:
由于各种原因最终使用了方案三,本地能够直接访问公司内网了,且速度能够接受,比使用 Windows Server 2016 的方案更好,但技术上也复杂不少。当有内网可使用 Wireguard 的机器时再切换为方案二,不考虑方案一是因为跨电信运营商时太慢。
Mac 的终端打造主要综合使用 iTerm + Shuttle + Expect 这三个软件:
iTerm 可匹配内容进行高亮显示、按下快捷键后窗口从屏幕上方滚动下来,请参考 iTerm 设置。
如下图设置配置 iTerm 的主题,请参考 Mac Terminal Powerlevel。
使用 Java 执行命令,可以:
下面以执行 ls -l / 为例演示相关代码。
1 | public static void executeCommandUsingProcessBuilder() throws Exception { |
疑问: 虽然如上能正常的获取到进程的正常和错误输出,慎用,因为缓冲区写满了的时候,由于没有读取其中的数据,无法继续写入数据,导致线程阻塞,对外现象就是进程无法停止,也不占资源,什么反应也没有,参考使用 JDK 写法。