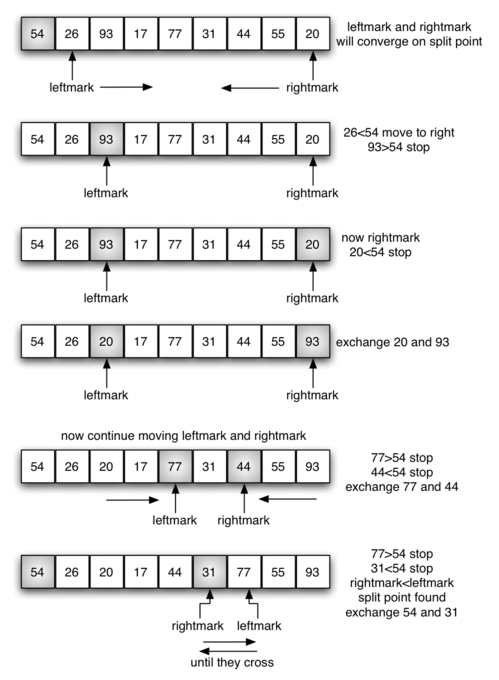
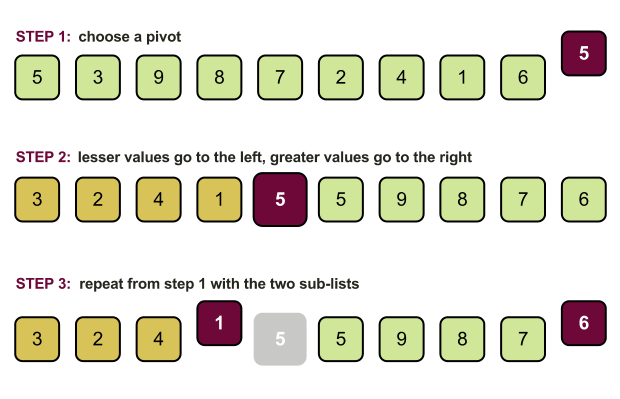/** * 使用快速排序对数组 a 中 low 到 high 之间的元素进行排序 */ publicstaticvoidquickSort(int[] a, int low, int high){ if (low < high) { int pivot = partition(a, low, high);
/** * 单边循环法分区 * * @return 返回分区的下标 pivot */ publicstaticintpartition(int[] a, int low, int high){ int pivot = a[low]; int mark = low; // mark 以及它前面的数据小于等于 pivot
for (int i = mark+1; i <= high; ++i) { if (a[i] <= pivot) { swap(a, ++mark, i); // 找到合适的数 a[i],区域 mark 扩大 1 个范围,然后交换 a[i] 和 a[mark] } }
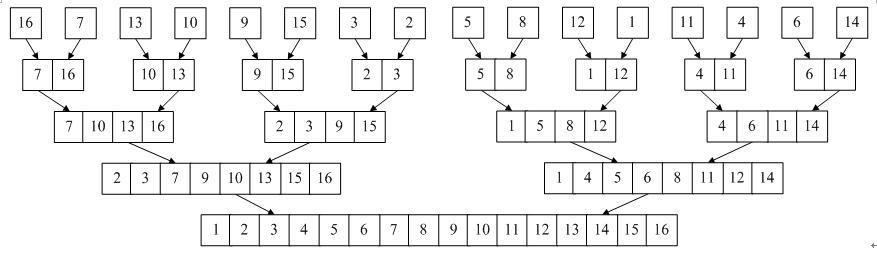
/** * 归并排序 */ publicstaticvoidmergeSort(int[] a){ int[] o = a; int[] t = newint[a.length];
for (int chunk = 1; chunk < a.length; chunk *= 2) { for (int l = 0; l < a.length; l += 2*chunk) { // 前 chunk 个元素和后续 chunk 个元素作为一组进行归并 (有序数组合并): [l,m) ~ [m,h) int m = Math.min(l+chunk, a.length); int h = Math.min(m+chunk, a.length); merge(a, l, m, h, t); }
// 一轮归并结束后, t 是此轮归并后的数组, 新一轮归并需要在前一轮归并的基础上进行 // 交互 a 和 t, 使得 a 是归并后的数组 int[] x = a; a = t; t = x; }
// 归并结束时, a 的数据是有序的, 但是此时 a 不一定指向传入进来的数组, 也就是说 a 不一定等于 o, // 需要复制数组 a 到原来的数组 o 中,这样函数外访问传入的数组才是排序后的有序数组 (引用使用传值传递) System.arraycopy(a, 0, o, 0, a.length); }
/** * 有序数组合并 * 把数组 a 中的 [l, m) 到 [m, h) 部分合并为有序数列到 t 的 [l, h) 中 */ publicstaticvoidmerge(int[] a, int l, int m, int h, int[] t){ int i = l; int j = m; int k = l;
while (i < m && j < h) { if (a[i] < a[j]) { t[k++] = a[i++]; } else { t[k++] = a[j++]; } }
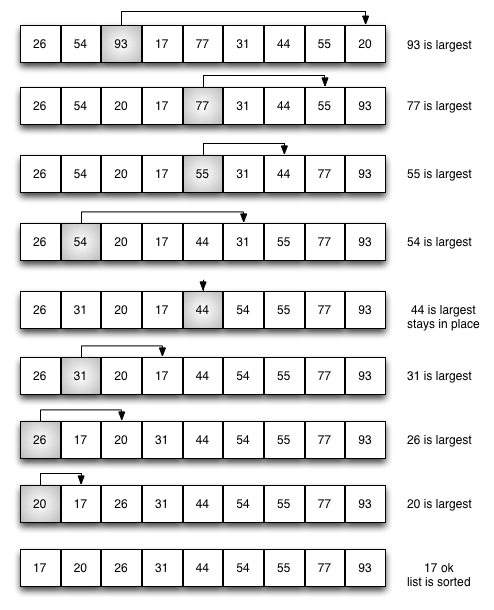
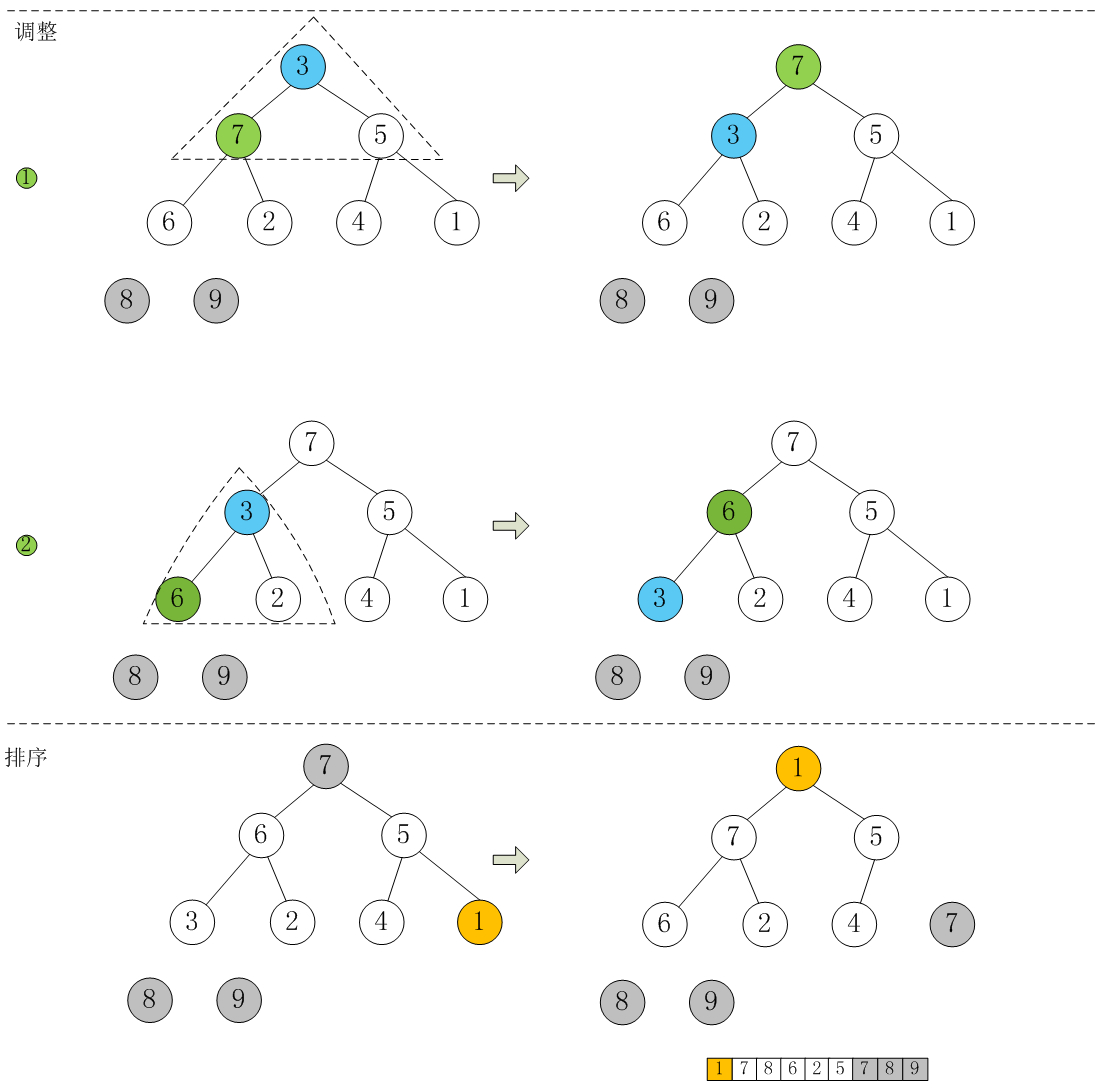
// a[0] 为最大的数,和最后一个交换,再把数组调整为大顶堆 for (int end = a.length-1; end > 0; --end) { swap(a, 0, end); adjustHeap(a, 0, end); } }
/** * 调整 a 为大顶堆, parent 的左右子树已经是大顶堆 */ publicstaticvoidadjustHeap(int[] a, int parent, finalint end){ int temp = a[parent];
for (int left = parent*2+1; left < end; left = parent*2+1) { // max 存储左右节点中最大数的下标 // left 存储左子节点的下标 // right 存储右子节点的下标 int max = left; int right = left + 1;
if (right<end && a[left]<a[right]) max = right; // 左右子节点中最大的数 if (temp >= a[max]) break; // parent 已经是最大值, 说明已经是大顶堆, 不需要再进行调整了