为什么要使用中文分词呢?
Solr 使用的是内置的一元分词 StandardAnalyzer,像 “诺基亚N95” 这样的词都能搜索到,我觉得它已经很不错了啊,为什么还要别的中文分词呢?
原因有以下几个方面:
- 采用标准分词器,每个字都会索引,造成索引量巨大
- 一元分词有个很严重的问题就是语意不准确,举一个简单例子,比如两个词 “上海” “海上”,这两个词都会拆分成 “海” 和 “上” 两个 term,那用户输入 “上海” 就一定会连带找到 “海上” 字条记录
- 索引大了自然效率就低
- 单个字是个求交集的过程,搜索效率也低
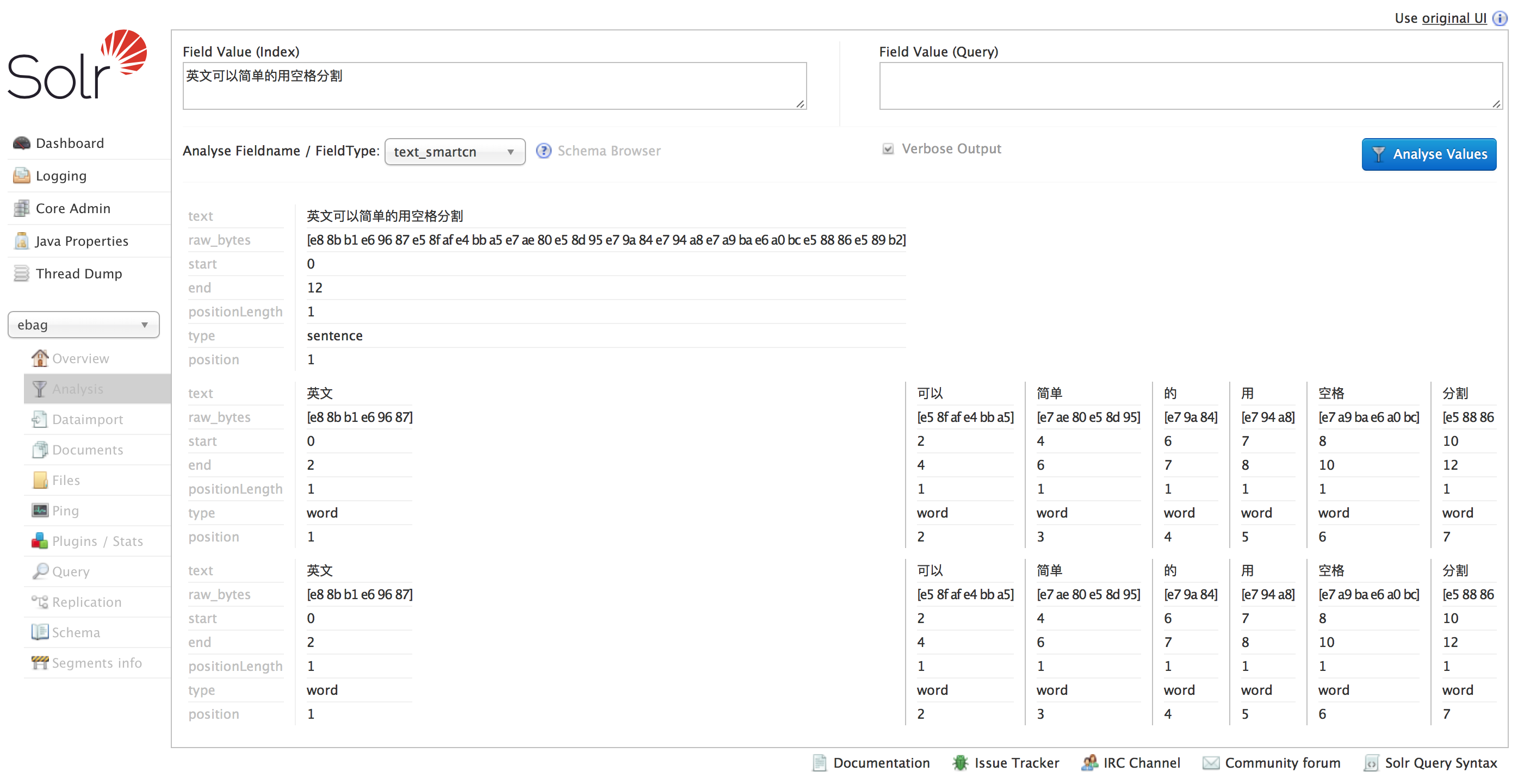
配置中文分词包
Solr 中默认的中文分词是用 Lucene 的一元分词包,下面介绍配置 Lucene 的 SmartCN 中文分词包(好像是由庖丁解牛演变而来)。
把
lucene-analyzers-smartcn-5.5.0.jar包复制到 solr 的启动目录的 lib 目录下:<solr_home>/server/solr-webapp/webapp/WEB-INF/lib/修改配置文件
<solr_home>/solr/ebag/conf/managed-schema,其中 ebag 是的 core 名称,在managed-schema文件的接近末尾的地方增加1
2
3
4
5
6
7<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>给需要使用中文分词的字段的 type 定义为
text_smartcn,增加下面的语句,比如 content 字段1
<field name="content" type="text_smartcn" indexed="true" stored="true"/>
重启 Solr 服务:
bin/solr restart验证 SmartCN 的分词效果