使用 html2pdf 把 Html 转为 Pdf,实际项目中可以先借助 Freemarker 模板生成 Html,然后再转换为 Pdf。
缺点: html2pdf 不支持 CSS 的 flex 和 grid 布局。
依赖
1 | implementation "com.itextpdf:html2pdf:2.1.7" |
转换
1 | import com.itextpdf.html2pdf.ConverterProperties; |

大圣,此去欲何?踏南天,碎凌霄。若一去不回…… 便一去不回!
使用 html2pdf 把 Html 转为 Pdf,实际项目中可以先借助 Freemarker 模板生成 Html,然后再转换为 Pdf。
缺点: html2pdf 不支持 CSS 的 flex 和 grid 布局。
1 | implementation "com.itextpdf:html2pdf:2.1.7" |
1 | import com.itextpdf.html2pdf.ConverterProperties; |
使用 Floyd 算法求任一点到其他所有点 (任意两点) 之间的最短距离: 对于每个顶点 v,和任一顶点对 (i, j), i!=j, v!=i, v!=j,如果 A[i][j] > A[i][v]+A[v][j],则将 A[i][j] 更新为 A[i][v]+A[v][j] 的值,并且将 Prev[i][j] 改为 Prev[v][j]:
min(Lik+Lkj, Lij),同时更新前驱表第一轮: 以 A 为中间节点,点 X 通过 A 到点 Y 的距离为 min(XA+AY, XY): BAA, BAB, BAC, BAD, BAE, BAF, BAG, CAA, CAB, …
第二轮: 以 B 为中间节点,…
…
第七轮: 以 G 为中间节点,…
1 | // 核心: Floyd 算法计算任意 2 点之间的最短距离 |
求图中一点到其他点的最短路径可使用 Dijkstra 算法 (使用广度优先策略):
Map<String, List<String>>: key 为节点名字,List 为邻接表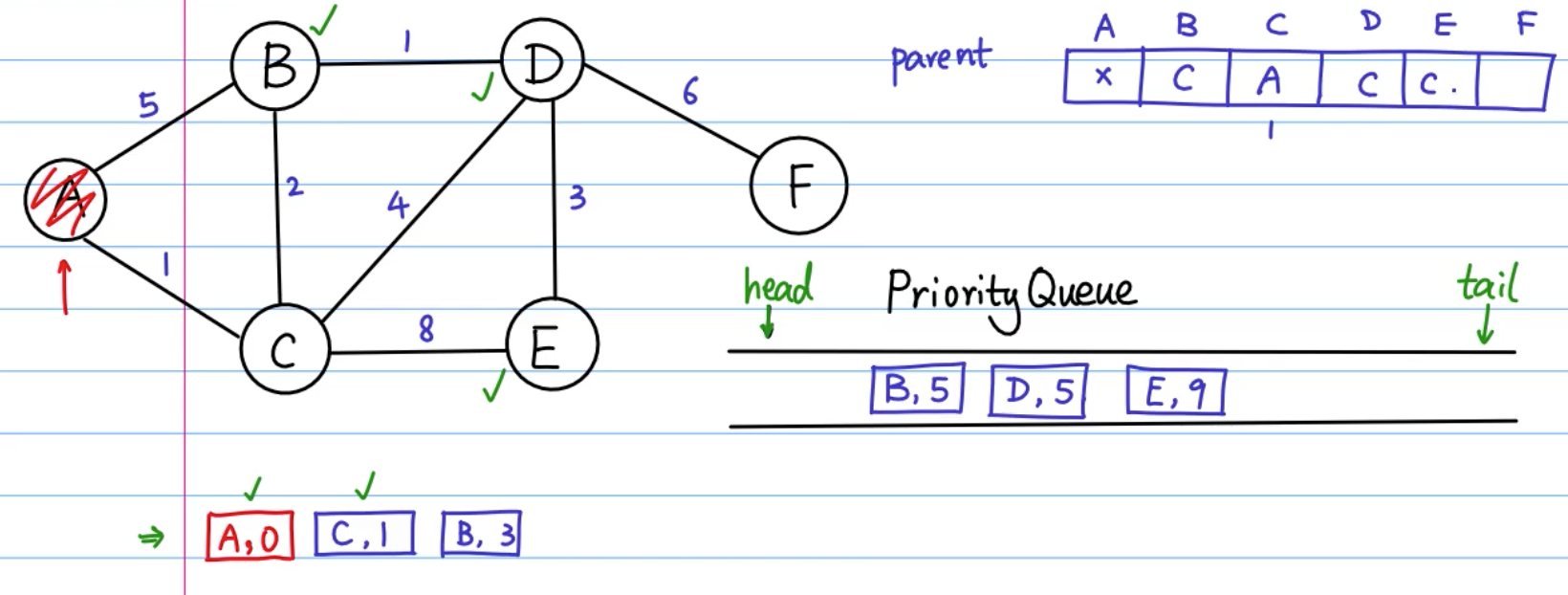
最小生成树 (Minumum Cost Spanning Tree,简称 MST) 的 2 个经典算法:
网: 带权无向图
最小生成树: 在包含 n 个顶点的连通图中,找出只有 (n-1) 条边,包含所有 n 个顶点的连通子图,也就是所谓的极小连通子图
下面图解 Prim 算法生成最小生成树的过程:
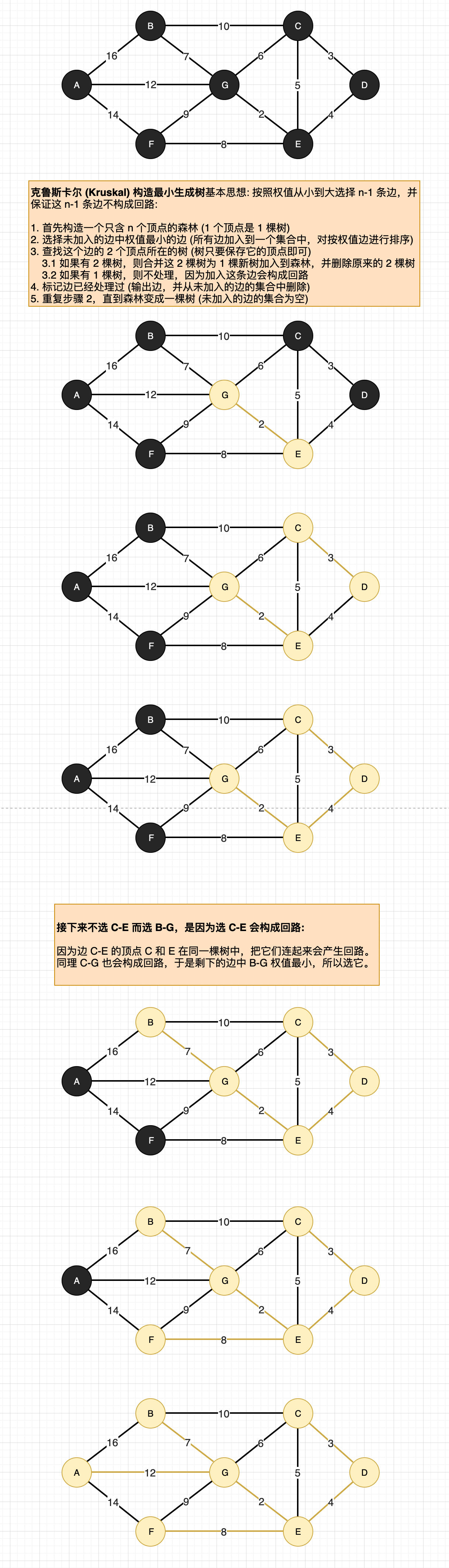
最小生成树 (Minumum Cost Spanning Tree,简称 MST) 的 2 个经典算法:
网: 带权无向图
最小生成树: 在包含 n 个顶点的连通图中,找出只有 (n-1) 条边,包含所有 n 个顶点的连通子图,也就是所谓的极小连通子图
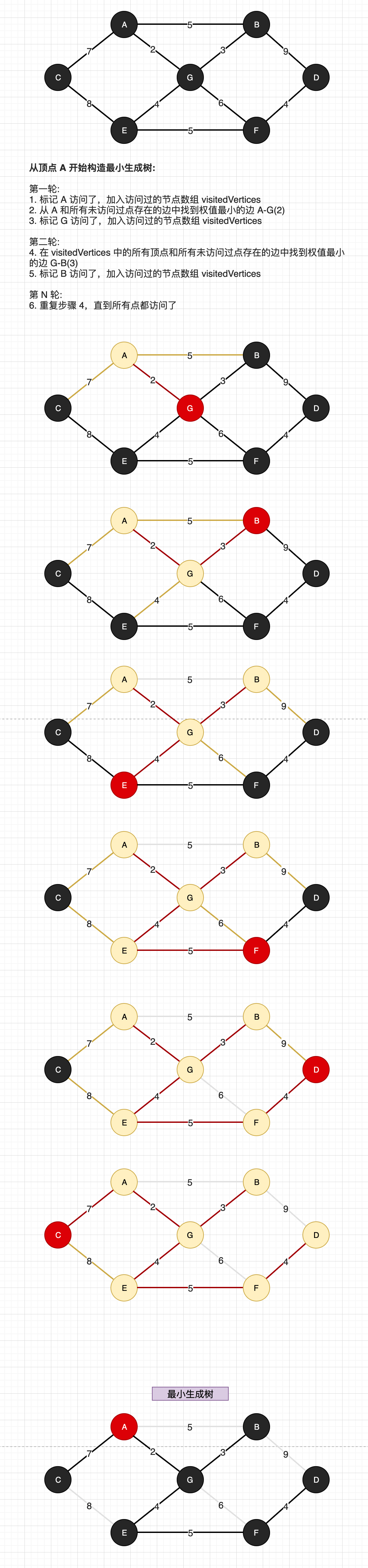
普里姆 (Prim) 算法求最小生成树算法如如下:
不管从哪一个顶点开始构建最小生成树,最后得到的最小生成树的边的权值加起来都相等。
下面图解 Prim 算法生成最小生成树的过程,其中:
为了方便创建图,可以把图的边按照格式 startVertex1-endVertex1:weight1,startVertex2-endVertex2:weight2 保存为一个字符串,例如 A-B:16,B-C:10,C-D:3,D-E:4,E-F:8,F-A:14,B-G:7,C-G:6,E-G:2,F-G:9,A-G:12,C-E:5,解析字符串得到图的所有边,使用邻接表存储图的数据。
1 | package graph; |
下面是顶点 A 的所有边:
1 | [{ |
使用 Brew 安装、使用 Docker 安装:
docker pull mysql:5.7.29docker run --name mysql -v /Users/Biao/Documents/workspace/Docker/mysql:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=root -p 3306:3306 -d mysql:5.7.29docker exec -it mysql bash,然后可以在里面执行 mysql -u root -p 访问 MySQL使用 Yum 安装、使用 Docker 安装
使用 Docker 安装,下面介绍安装解压版:
在 mysql 的根目录创建 data 目录和 my.ini 配置文件,参考最后面的配置文件内容
以管理员身份运行 cmd(一定要用管理员身份运行,不然权限不够),通过命令,进入 mysql bin 目录 (参考安装 MySQL)
输入 mysqld --initialize-insecure --user=mysql 回车,初始化 MySQL
输入 mysqld --install 回车,把 MySQL 安装为系统服务
如果系统重装后,不需要再次初始化 MySQL,只需要再次安装为系统服务即可。
启动 MySQL: 输入 net start mysql 回车,启动 MySQL 服务,start 启动,stop 停止。启动出错时可参考 net start mysql发生系统错误 2,找不到指定文件
输入 mysql -u root -p ,回车,出现 Enter passwore: ,输入密码,由于刚安装,没有设置密码,直接回车 Enter 进入
1 | use mysql; |
配置文件 my.ini 的内容:
1 | [WinMySQLAdmin] |
注意: Windows 下必须配置
[WinMySQLAdmin]。
在 [mysqld] 部分加入下面的配置开启 binlog:
1 | [mysqld] |
更多信息请参考 Windows 环境 MySQL 开启 binlog 日志方法。
在学习二叉树、二叉排序树、AVL 树、红黑树等时,如果能够直观的看到树的结构,对于学习有非常大的帮助。利用 binary-tree-printer 化打印可视化的二叉树,更多方案可参考 How to print binary tree diagram?
1 | implementation "com.github.afkbrb:binary-tree-printer:1.0.0" |
打印完全二叉树:
1 | BTPrinter.printTree("1,2,3,4,5,#,#,6,7,8,1,#,#,#,#,#,#,2,3,4,5,6,7,8,9,10,11,12,13,14,15"); |
1 | 1 |
使用阿里云 OSS 存储图片: